nREPL Middleware
In this post, I have tried to cover what nREPL is, what nREPL Middleware are and why we need them. We will
also look at the middleware provided by cider-nrepl and in the end, we will write our own custom middleware.
If you write Clojure, you are most probably using nREPL as that is the most popular REPL out there. But it is not the only REPL out there.
The Clojure REPL
Clojure itself has its own REPL. To start the default Clojure REPL, just run the clojure on
your terminal. You will see a REPL prompt. This is the default Clojure REPL.
Try (println "Hello, world!") and you will see it works just like any other REPL.
But there are a few problems with this REPL. It does not support some basic features like autocompletion or line editing (visiting previously typed text with up arrow)
Line editing will work if you use the
cljcommand, but it is just a wrapper overclojurewithrlwrap.
If you read man clojure, you will also notice that there is no easy way to start this
REPL on a socket. So if you are using this REPL, you cannot connect to it from remote machines.
So the default REPL clearly cannot be used as your daily development REPL. That is where the need for other types of REPLs comes in.
nREPL
Network REPL (nREPL) is a huge improvement over the default Clojure REPL. nREPL has a client server design. As the name suggests, an nREPL server can be started on a socket so that remote clients can connect to it. It also gives you support for autocompletion, symbol lookups and many more things.
If you use Emacs, you can see the communication between the client and the server by executing the following Elisp code:
(setq nrepl-log-messages t)If you don’t know how to run the above code, just press
M-:(which runseval-expression) in any buffer, paste the above code in the input minibuffer and pressRET.
This will tell the nREPL client in Emacs to log the messages passed between the client and
the server. Now run (println "Hello, world!") in the REPL and then switch to the buffer
with this name:
*nrepl-messages <projectname>:<host>:<port>*
This buffer lists all the messages sent by the client and the replies sent by the
server.
When we executed (println "Hello, world!"), the
client sent this message:
(-->
id "9"
op "eval"
session "ed9decc8-200a-4a80-aec7-025050a8ff4b"
time-stamp "2020-07-31 20:09:42.624467000"
code "(println \"Hello, world!\")"
column 1
file "*cider-repl workspace/cider-nrepl:localhost:57021(clj)*"
line 2
nrepl.middleware.print/buffer-size 4096
nrepl.middleware.print/options (dict ...)
nrepl.middleware.print/print "cider.nrepl.pprint/pprint"
nrepl.middleware.print/quota 1048576
nrepl.middleware.print/stream? "1"
ns "user"
)Messages starting with
-->are requests from client. And those starting with<--are replies from server.
The messages buffer will contain some other messages as well. But we will focus on the messages that I’ve mentioned here.
So what does this tell us?
The most important field in any message sent by the client is the op field. This field
tells the server what operation is to be performed. Depending on the op, there will be
other fields that that particular op depends on.
In the above message, the op is eval. From eval, the server understands that it has
to evaluate some code. It expects the client to send the code to be evaluated in code
field. You can see that the code field contains the code which we had run: "(println \"Hello, world!\")".
The session field represents the ID of the current session. Every client has a separate
session ID with the server so that the server can identify multiple clients
separately. The id field is the ID of the request. Every request has a separate ID. The
server uses the same id in its replies so that clients can map requests and replies. So
to look at the replies from server, let’s use the id field (at your end, id will most
probably be a different number). Here are the replies from the server:
(<--
id "9"
session "ed9decc8-200a-4a80-aec7-025050a8ff4b"
time-stamp "2020-07-31 20:09:43.156831000"
out "Hello, world!"
)
(<--
id "9"
session "ed9decc8-200a-4a80-aec7-025050a8ff4b"
time-stamp "2020-07-31 20:09:43.184731000"
value "nil"
)There will be another 3 messages with the same
id, but those are not important for this discussion.
The first message tells the client that "Hello, world!" is printed on out
(stdout). The second message tells that the return value of the executed expression was
nil (println returns nil).
This feature of being able to look at client server communication comes in handy at times.
Now that we have looked at basics of client server communication, we can jump to the biggest feature that nREPL provides - support for custom middleware.
nREPL Middleware
nREPL Middleware gives you the ability to add your own middleware to support your own operations. What this essentially means is that you can write code (which will run on the server side) which can read requests from clients and then send appropriate responses.
So for example, if you wanted nREPL to show you ClojureDocs, you could write your own operation, say clojure-docs,
which would take a symbol to be searched, as input (in the client message) and return
the doc in the server reply.
This is exactly how cider-nrepl adds a whole lot of functionality to
nREPL. cider-nrepl is a collection of middleware.
CIDER nREPL
If you are using cider in Emacs, you are already using the cider-nrepl middleware.
Let’s dig deeper into an operation provided by cider-nrepl - autocomplete.
If you type print, you will see autocompletions similar to this:
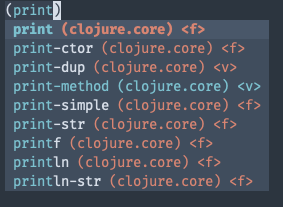
Let’s look at the messages for this. To get completions for print, the client sends this message:
(-->
id "58"
op "complete"
session "ed9decc8-200a-4a80-aec7-025050a8ff4b"
time-stamp "2020-07-31 22:31:59.822565000"
context ":same"
enhanced-cljs-completion? "t"
ns "user"
prefix "print"
)The op is complete, and op specific keys are prefix and ns. prefix is the text
to be completed and ns is the current namespace in the REPL. This is important because
completions are depedent on the current namespace.
Here is the message from the server:
(<--
id "58"
session "ed9decc8-200a-4a80-aec7-025050a8ff4b"
time-stamp "2020-07-31 22:31:59.826961000"
completions ((dict "candidate" "print" "ns" "clojure.core" "type" "function")
(dict "candidate" "printf" "ns" "clojure.core" "type" "function")
(dict "candidate" "println" "ns" "clojure.core" "type" "function")
(dict "candidate" "print-dup" "ns" "clojure.core" "type" "var")
(dict "candidate" "print-str" "ns" "clojure.core" "type" "function")
(dict "candidate" "print-ctor" "ns" "clojure.core" "type" "function")
(dict "candidate" "println-str" "ns" "clojure.core" "type" "function")
(dict "candidate" "print-method" "ns" "clojure.core" "type" "var")
(dict "candidate" "print-simple" "ns" "clojure.core" "type" "function"))
status ("done")
)The server is providing detailed information about the completions in the completions
key. For every completion, it is telling what the completion text is, which namespace it
comes from and the type of completion candidate (var or function). Now if you look at the
screenshot above, you can see that print-method has a <v> at the end - signifying that
it is a var. This is based on the type information sent by the server.
These two messages give us a fair idea about how the operation must be implemented. If I were to guess how the implementation of nREPL Middleware must be, I would guess it to be something like the following:
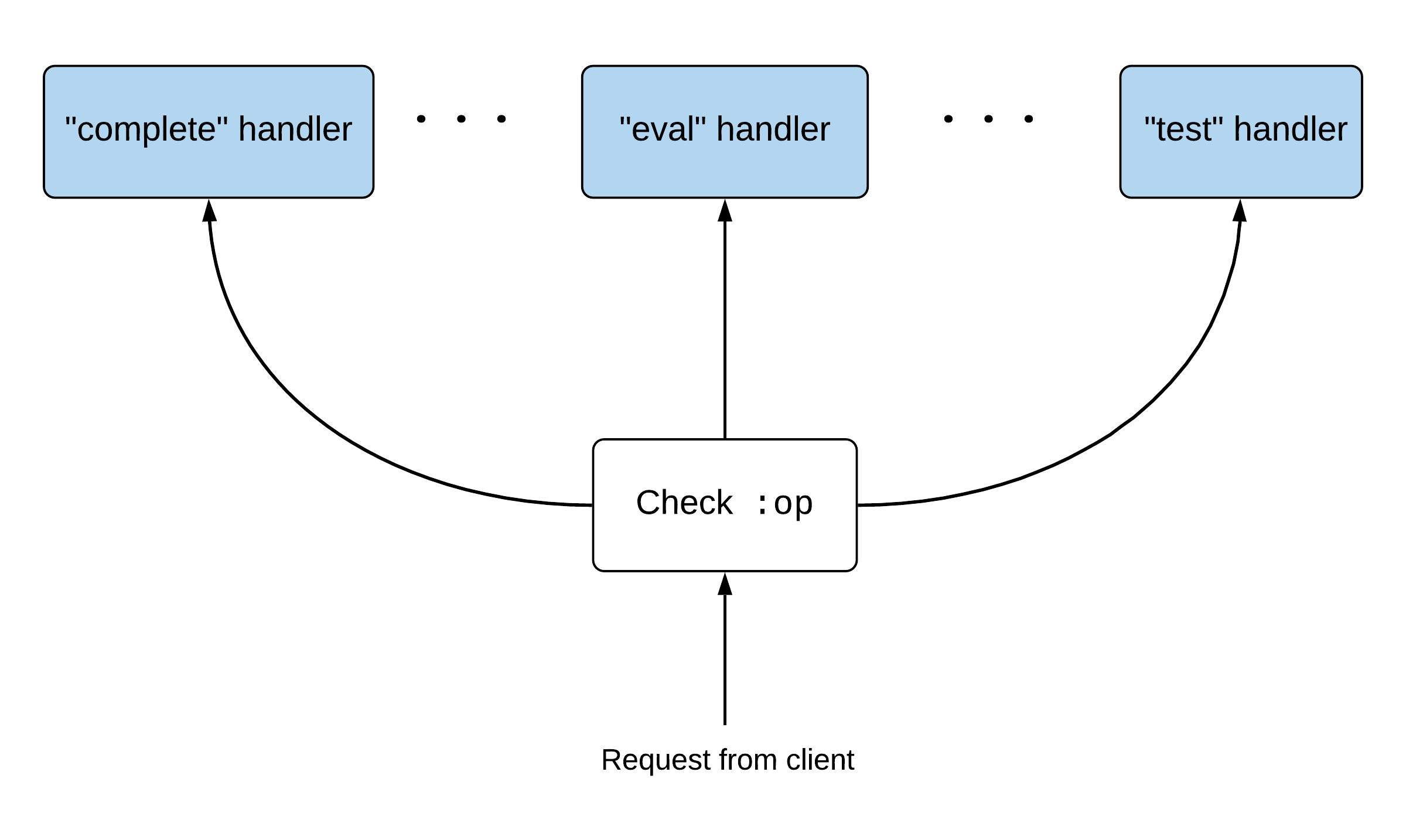
Depending on the operation, requests would be routed to respective handlers. And to add a new handler, you would register the operation and the handler function with nREPL.
But that is not the case. There is one small point which is a bit counter intuitive. The architecture is similar to how Ring middleware works. It looks like this:
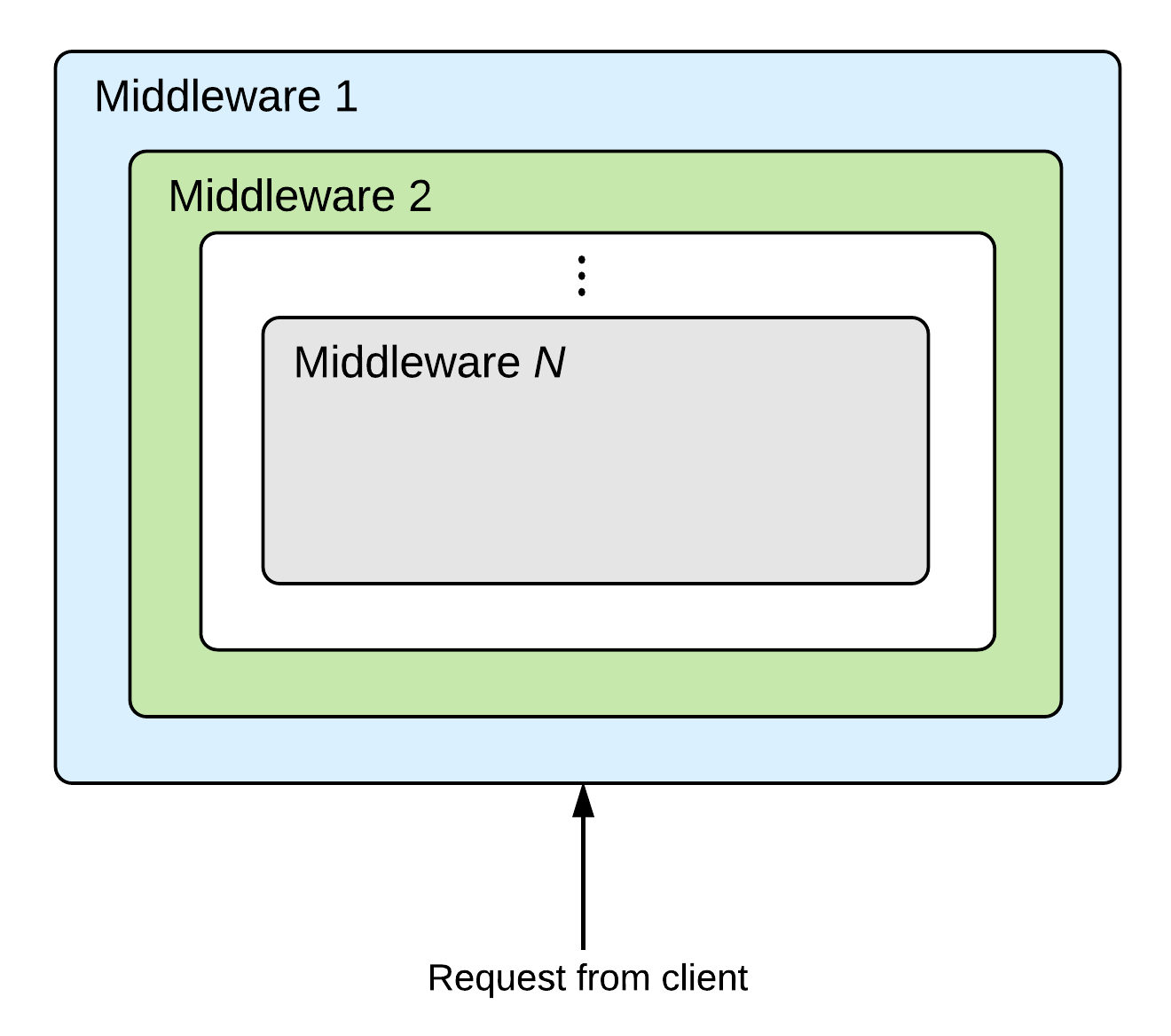
This type of architecture enables multiple handlers being able to take part in serving a
request. For example, a complete request from a client, will be handled by the session
middleware (to track the session) and also by the completion middleware (to provide
completions).
With that, we can now proceed to writing our own middleware.
Writing Your Own Middleware
While writing Clojure, we sometimes need to examine macroexpanded code. So let’s write a
simple middleware which will give you macroexpanded code. The op will be
macroexpansion (not naming it macroexpand since cider-nrepl already has it). It will
take code to be expanded as input and it will send back macroexpanded code. To achieve
this, let’s create a new namespace and write the following code in it:
(ns nrepl-playground.macroexpansion ;; Your ns name could be different
(:require [clojure.walk :as walk]
;; You'll need to add `nrepl` in your dependenciess
[nrepl.middleware :refer [set-descriptor!]]
[nrepl.misc :refer [response-for]]
[nrepl.transport :as t]))
(defn- handle-macroexpansion
[{:keys [transport code] :as msg}]
(let [expanded-code (walk/macroexpand-all (read-string code))]
(t/send transport (response-for msg
:status :done
:expanded-code (str expanded-code)))))
(defn wrap-macroexpansion
[handler]
(fn [{:keys [op] :as msg}]
(if (= "macroexpansion" op)
(handle-macroexpansion msg)
(handler msg))))
(set-descriptor! #'wrap-macroexpansion
{:requires #{}
:expects #{}
:handles {"macroexpansion"
{:doc "Get macroexpanded code"
:requires {"code" "code to be macroexpanded"}
:optional {}
:returns {"expanded-code" "macroexpanded code"}}}})Let’s look at what we are doing here. Our handler is handle-macroexpansion. Middleware
handler should be a function which accepts msg as its input. This will the message sent
by client. So we are extracting code from it. Then we are macroexpanding the code and
sending it back to the client.
The wrap-macroexpansion function is the middleware function. If the op is
macroexpansion we pass the message to our handler, otherwise we pass control to the next
handler.
The call to set-descriptor! tells nREPL to set this middleware. The second parameter is
the middleware descriptor - a map containing details about the middleware. requires
should be a set containing middleware vars or strings (ops) which need to be run before
your middleware. excepts should be a set containing middleware vars or strings (ops)
which need to be run after your middleware. This is how the order of middleware is
decided.
For example, if your middleware depends on other middleware, for example, if it depends on
the session middleware, you will put requires as #{'session}. If your middleware
expects eval middleware to be called after your middleware executes, you will write
expects as #{"eval"}.
Our middleware does not depend on any other middleware, nor does it expect any other middleware to be executed later. So for us, both of these sets are empty.
handles is used for documenting the middleware. This map should have operations (as
strings) it handles as its keys ("macroexpansion" in our case) and values should be maps
describing those operations:
{:doc <description of your opearation>
:requires <map of required things it expects in msg>
:optional <map of optional things it expects in msg>
:returns <map of return values it puts in msg>}But calling set-descriptor! is not enough. Middleware stack cannot be modified
dynamically once nREPL starts. So to tell Leiningen to add this middleware to nREPL
before starting the server, you will need to add this to your project file:
:repl-options {:nrepl-middleware
[nrepl-playground.macroexpansion/wrap-macroexpansion]}You will need to restart your REPL for the middleware to take effect. There is a way to enable dynamic middleware loading, but that is a topic for another blog post.
After you start the REPL, connect to it from Emacs. From the REPL buffer (or from any
other Clojure file buffer from the running project), press M-: (which runs
eval-expression) and in the prompt, type the following and press RET:
(cider-nrepl-send-sync-request `("op" "macroexpansion"
"code" "(defn add [a b] (+ a b))"))
cider-nrepl-send-sync-requestis a function provided bycider- the Emacs client forcider-nrepl- to send messages to the REPL server.
You will see the reply message in the minibuffer but it won’t be much readable in a single line. So switch to the messages buffer and you should find messages similar to these:
(-->
id "124"
op "macroexpansion"
session "aedffa41-cbfa-4577-8450-864c8fb06349"
time-stamp "2020-08-20 22:03:28.467298000"
code "(defn add [a b] (+ a b))"
)
(<--
id "124"
session "aedffa41-cbfa-4577-8450-864c8fb06349"
time-stamp "2020-08-20 22:03:28.470777000"
expanded-code "(def add (fn* ([a b] (+ a b))))"
status ("done")
)You can see that expanded-code has the macroexpanded code for the code we had sent in
the request. Our middleware is working! :)
Conclusion
In this post, we saw:
- Why was there a need to have REPLs other than Clojure’s default REPL.
- How nREPL provides extensibility with support for custom middleware.
- How to look at client-server messaging with Emacs +
cider. - Architecture of nREPL Middleware.
- How to add a custom middleware.
Now whenever you feel like some functionality is missing from your Clojure development setup and if you feel adventurous, go ahead and implement it as a middleware! :)